
This is a technical explanation of procedure to map parking infractions in Manhattan for every available car make. To see the interactive visualization, click here, or click the image below. Otherwise read on.
Last year I published an Android app to enable Slovenian drivers to better avoid areas frequently inspected by parking wardens. It works by geolocating the user and then plotting issued paring tickets in the vicinity, with a breakdown by month, time of day and temperature on another screen. It was not a huge hit, but it did reasonably well for such a small country and no marketing budget.
I was thinking of making a version for New York City, but then abandoned the project. These visualizations are all that remains of it.
I started with downloading the data from New York Open Data repository. It’s here. The data is relatively rich, but it’s not geocoded. Luck had it that Mapbox just rolled out a batch geocoder at that time, and it was free with no quotas. So I quickly sent around 100,000 adresses through it and saved the results in a database for later use. The processed result is now available on Downloads page in form of JSON files, one per car make.
The actual drawing procedure was easier than I thought. I downloaded street data from New York GIS Clearinghouse and edited out everything but Manhattan with QGis.
First I tried a promising matrix approach, but I was unable to rotate the heatmap so that it would make sense. Here’s an example for Audi:

As you can see, it is a heatmap, but doesn’t look very good.
So I wrote a Python script that went through all street segments and awarded a point if there was an infraction closer that 100 meters from the relevant segment. Then I just used matplotlib to draw all the street segments, coloring them according to the maximum segment value.
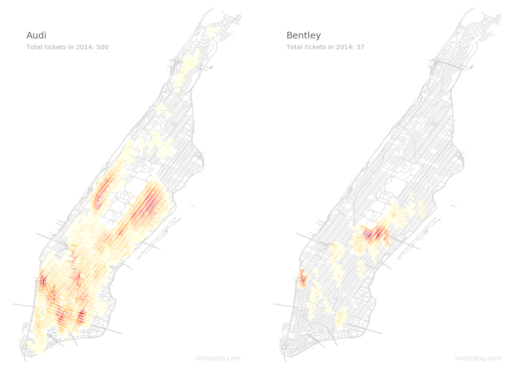
A result for Audi now looks like this:

All that remained was drawing required images for animated GIFs, each for every hour for every car make. This was done with minimal modifications to original script (I learned Python multithreading in the process). The resulting images were then converted to animated GIFs with ImageMagic.
The whole procedure took approximately 12h of calculating and rendering time on a i7-6700 with 32 GB RAM. I guess I could shave several hours from that time, but I just let it run overnight.
See interactive version here, and tell me what you think in the comment section, if you feel like it.








































